Gjennomsnittlig tid til utbedring (MTTR)
TL;DR
- MTTR representerer den gjennomsnittlige tiden som kreves for å løse en sikkerhetssårbarhet etter identifikasjon, og gir et direkte mål på operasjonell effektivitet.
- For å beregne MTTR, del den totale tiden brukt på å fikse problemer med antall hendelser.
- Målet er å minimere eksponeringstiden slik at angripere er mindre sannsynlige til å utnytte kjente hull.
- Løsningen er å akselerere prosessen ved å automatisere alt fra sårbarhetsdeteksjon til generering av kodefikser, eliminere forsinkelser i manuelle billettkøer og sikre raskere utbedring.
Hva er MTTR?
Gjennomsnittlig tid til utbedring (MTTR) er en viktig cybersikkerhetsmåling som viser hvor raskt du reagerer på en kjent trussel. Den måler tiden fra når en sårbarhet blir funnet til når en fiks er implementert.
Mens målinger som MTTD reflekterer deteksjonshastighet, avslører MTTR din organisasjons sanne utbedringseffektivitet. Rask deteksjon må matches med rask løsning for å begrense risikoutsatthet og støtte forretningskontinuitet.
Hvorfor MTTR er viktig
Cyberkriminelle opererer raskere enn tradisjonelle utviklingstidslinjer, noe som øker behovet for responsive sikkerhetsoperasjoner. Industrielle trender indikerer at forsvarsvinduer krymper.
- 5-dagers utnyttelsesvindu: I 2025 falt den gjennomsnittlige Tiden til Utnyttelse (TTE), gapet mellom når en sårbarhet blir offentliggjort og når den aktivt utnyttes, fra 32 dager til bare 5 dager (CyberMindr, 2025).
- Økning i utnyttelse: Bruken av sårbarheter som en inngangsmetode har økt med 34 % i år og forårsaker nå 20 % av alle bekreftede brudd.
- Forsinkelse i utbedring: Angripere handler i løpet av dager, men organisasjoner tar ofte uker. Median tid for å fikse kritiske sårbarheter i kant- og VPN-enheter er fortsatt 32 dager, noe som etterlater et betydelig risikovindu. Bare 54 % av feilene blir noen gang fullstendig rettet (Verizon DBIR, 2025). Dagakselerasjon: Oppdagelsen av utnyttede null-dagers sårbarheter økte med 46 % sammenlignet med i fjor. Angripere våpeniserer nå disse feilene innen timer etter identifikasjon (WithSecure Labs, 2025).
- Høy MTTR øker forretningskostnadene langt utover teknisk gjeld. I 2025 er den gjennomsnittlige kostnaden for et datainnbrudd i USA 4,4 millioner dollar, hovedsakelig på grunn av forsinket respons og regulatoriske straffer (IBM, 2025).
- Samsvarsstraffer: Under regler som DORA, regnes lange eksponeringstider som feil under operasjonell motstandskraft. Organisasjoner med høy MTTR står nå overfor obligatorisk rapportering og store bøter for manglende samsvar. Du kan ikke bevege deg raskere enn utnyttelsesskriptene; ditt forsvar er rent teoretisk.
Hvordan beregne MTTR
MTTR beregnes ved å dele den totale tiden brukt på å reparere et system med antall reparasjoner utført over en spesifikk periode.
Formelen
{kind=link}
Beregningseksempel
Tenk deg at ingeniørteamet ditt håndterte 4 hendelser forrige måned:
- Hendelse A: Databaseutfall (Fikset på 30 minutter)
- Hendelse B: API-feil (Fikset på 2 timer / 120 minutter)
- Hendelse C: Cache-feil (Fikset på 15 minutter)
- Hendelse D: Sikkerhetspatch (Fikset på 45 minutter)
- Total reparasjonstid: 30 + 120 + 15 + 45 = 210 minutter
- Antall reparasjoner: 4
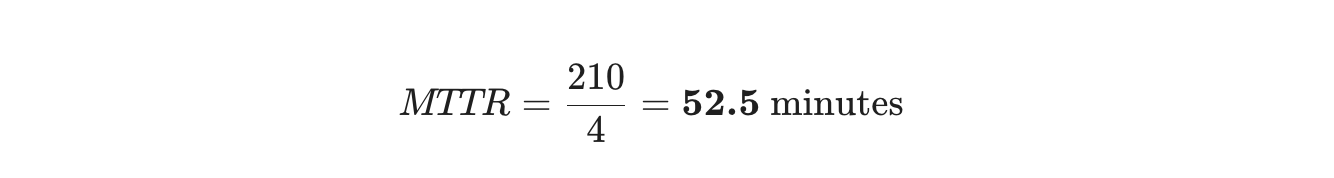{kind=link}
Dette betyr at det i gjennomsnitt tar teamet ditt omtrent 52 minutter å fikse et problem når de begynner å jobbe med det.
Eksempel i praksis
Tenk på to selskaper som står overfor en kritisk sikkerhetssårbarhet (f.eks. Log4Shell).
Selskap A (Høy MTTR):
- Prosess: Manuell. Varsler går til e-post. En ingeniør må manuelt SSH inn på servere for å finne de sårbare jar-filene og patche dem én etter én.
- MTTR: 48 timer.
- Resultat: Angripere har to hele dager på seg til å utnytte sårbarheten. Data er sannsynligvis kompromittert.
Selskap B (Lav MTTR - bruker Plexicus for å automatisere utbedring):
- Prosess: Automatisert. Sårbarheten oppdages umiddelbart. En automatisert playbook utløses for å isolere berørte containere og anvende en patch eller virtuell brannmurregel.
- MTTR: 15 minutter.
- Resultat: Sårbarheten lukkes før angripere kan lansere et vellykket angrep.
Hvem bruker MTTR
- DevOps-ingeniører - For å spore effektiviteten av deres distribusjons- og tilbakestillingspipelines.
- SREer (Site Reliability Engineers) - Sikrer at de oppfyller SLAer (Service Level Agreements) for oppetid.
- SOC-analytikere - For å måle hvor raskt de kan nøytralisere aktive sikkerhetstrusler.
- CTOer & CISOer - For å rettferdiggjøre investeringer i automatiseringsverktøy ved å vise en reduksjon i gjenopprettingstid.
Når man skal anvende MTTR
MTTR bør overvåkes kontinuerlig, men det er mest kritisk under Hendelsesrespons-fasen av SDLC (Software Development Life Cycle)
- Under hendelser: Det fungerer som en live pulssjekk. “Fikser vi dette raskt nok?”
- Post-mortem: Etter en hendelse hjelper det å gjennomgå MTTR med å identifisere om forsinkelsen ble forårsaket av deteksjon av problemet (MTTD) eller fikse det (MTTR).
- SLA-forhandling: Du kan ikke love en kunde “99,99% oppetid” hvis din gjennomsnittlige MTTR er 4 timer.
Beste praksis for å redusere MTTR
- Automatiser alt: Manuelle rettelser er trege og utsatt for feil. Bruk Infrastructure as Code (IaC) for å gjenopprette ødelagt infrastruktur i stedet for å fikse det manuelt.
- Bedre overvåking: Du kan ikke fikse det du ikke kan se. Granulære observasjonsverktøy hjelper med å finne rotårsaken raskere, noe som reduserer “diagnose”-delen av reparasjonstiden.
- Runbooks & Playbooks: Ha forhåndsskrevne guider for vanlige feil. Hvis en database låser seg, skal ikke ingeniøren måtte Google “hvordan låse opp en database.”
- Skyldfrie etteranalyser: Fokuser på prosessforbedring, ikke mennesker. Hvis ingeniører frykter straff, kan de skjule feil, noe som gjør MTTR-metrikker unøyaktige.
Relaterte termer
- MTTD (Mean Time To Detect)
- MTBF (Mean Time Between Failures)
- SLA (Service Level Agreement)
- Hendelseshåndtering
Vanlige myter
-
Myte: Du kan oppnå “null sårbarheter.”
Virkelighet: Målet er å fikse kritiske problemer raskt nok til å unngå utnyttelse.
-
Myte: Flere skannere gir bedre sikkerhet.
I virkeligheten skaper det bare mer støy og manuelt arbeid hvis ikke integrert.
-
Myte: Sikkerhetsverktøy bremser utviklere.
Virkelighet: Sikkerhet bremser bare utviklere når det genererer “ødelagte” varsler. Når du gir en forhåndsskrevet pull request, sparer du dem timer med forskning.
FAQ
Hva er en “god” MTTR?
Topp DevOps-team sikter mot en MTTR på under 24 timer for kritiske sårbarheter.
Hvordan skiller MTTR seg fra MTTD?
MTTD (Mean Time to Detect) viser hvor lenge en trussel er til stede før du legger merke til den. MTTR viser hvor lenge den forblir etter at du har funnet den.
Kan AI faktisk hjelpe med MTTR?
Ja. AI-verktøy som Plexicus håndterer triage og foreslår løsninger, som vanligvis utgjør 80% av utbedringsprosessen.
Avsluttende tanke
MTTR er hjerteslaget i ditt sikkerhetsprogram. Hvis det er høyt, er risikoen din høy. Ved å automatisere overgangen fra å finne problemer til å opprette pull requests, slutter du å behandle sikkerhet som en flaskehals og begynner å behandle det som en normal del av din CI/CD-pipeline.