修复平均时间 (MTTR)
TL;DR
- MTTR 代表在识别安全漏洞后解决问题所需的平均时间,直接衡量运营效率。
- 计算 MTTR 的方法是将修复问题所花费的总时间除以事件数量。
- 目标是尽量减少暴露时间,以降低攻击者利用已知漏洞的可能性。
- 解决方案是加速流程,通过自动化从漏洞检测到代码修复生成的全过程,消除手动票据队列中的延迟,确保更快的修复。
什么是 MTTR?
修复平均时间 (MTTR) 是一个关键的网络安全指标,显示您对已知威胁的响应速度。它衡量从发现漏洞到实施修复的时间。
虽然像 MTTD 这样的指标反映了检测速度,但 MTTR 揭示了组织的真正修复效率。快速检测必须与及时解决相匹配,以控制风险暴露并支持业务连续性。
为什么 MTTR 重要
网络犯罪分子的行动速度比传统开发时间表更快,这加速了对响应性安全操作的需求。行业趋势表明,防御窗口正在缩小。
- 5天漏洞利用窗口期: 在2025年,平均漏洞利用时间(TTE),即漏洞公开到被积极利用之间的时间,从32天缩短到仅5天(CyberMindr, 2025)。
- 利用激增: 今年通过漏洞作为入侵手段的使用增加了34%,现在导致了所有确认的漏洞中有20%的发生。
- 修复滞后: 攻击者在几天内行动,但组织通常需要数周时间。修复边缘和VPN设备中关键漏洞的中位时间仍为32天,留下了显著的风险窗口。只有54%的缺陷被完全修复(Verizon DBIR, 2025)。天数加速: 被利用的零日漏洞的发现比去年增加了46%。攻击者现在在识别后数小时内将这些缺陷武器化(WithSecure Labs, 2025)。
- 高MTTR推高了业务成本,远超技术债务。2025年,美国数据泄露的平均成本为440万美元,主要由于响应延迟和监管处罚(IBM, 2025)。
- 合规处罚: 根据DORA等规则,长时间暴露被视为运营弹性失败。高MTTR的组织现在面临强制报告和巨额不合规罚款。你无法比漏洞利用脚本更快;你的防御纯属理论。
如何计算MTTR
MTTR的计算方法是将系统维修总时间除以特定时期内执行的维修次数。
公式
{kind=link}
计算示例
假设您的工程团队上个月处理了4个事件:
- 事件A: 数据库中断(修复时间为30分钟)
- 事件B: API故障(修复时间为2小时 / 120分钟)
- 事件C: 缓存错误(修复时间为15分钟)
- 事件D: 安全补丁(修复时间为45分钟)
- 总维修时间: 30 + 120 + 15 + 45 = 210分钟
- 维修次数: 4
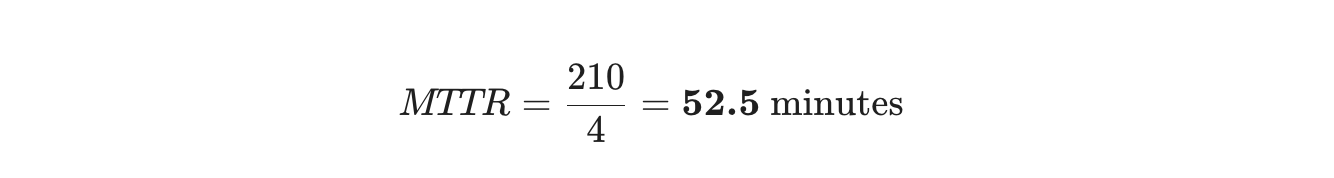{kind=link}
这意味着,平均来说,您的团队一旦开始工作,修复一个问题大约需要52分钟。
实践中的示例
考虑两个公司面临一个关键的安全漏洞(例如,Log4Shell)。
公司A(高MTTR):
- 流程: 手动。警报发送到电子邮件。工程师必须手动SSH进入服务器,找到易受攻击的jar文件并逐一修补。
- MTTR: 48小时。
- 结果: 攻击者有整整两天的时间来利用漏洞。数据可能被泄露。
公司B(低MTTR - 使用Plexicus自动化修复):
- 过程: 自动化。漏洞被立即检测到。一个自动化的剧本触发,隔离受影响的容器并应用补丁或虚拟防火墙规则。
- MTTR: 15分钟。
- 结果: 在攻击者能够成功利用漏洞之前,漏洞已被关闭。
谁使用MTTR
- DevOps工程师 - 用于跟踪其部署和回滚管道的效率。
- SRE(站点可靠性工程师) - 确保他们满足正常运行时间的SLA(服务水平协议)。
- SOC分析师 - 用于衡量他们中和活跃安全威胁的速度。
- CTO和CISO - 通过展示恢复时间的减少来证明对自动化工具的投资合理性。
何时应用MTTR
MTTR应被持续监控,但在SDLC(软件开发生命周期)的事件响应阶段最为关键。
- 事件期间: 它充当实时脉搏检查。“我们修复得够快吗?”
- 事后分析: 事件后,审查MTTR有助于识别延迟是由检测问题(MTTD)还是修复问题(MTTR)引起的。
- SLA谈判: 如果您的平均MTTR是4小时,您不能向客户承诺“99.99%的正常运行时间”。
减少MTTR的最佳实践
- 自动化一切: 手动修复速度慢且容易出错。使用基础设施即代码(IaC)重新部署损坏的基础设施,而不是手动修复。
- 更好的监控: 看不见就无法修复。细粒度的可观察性工具有助于更快地找出根本原因,减少修复时间中的“诊断”部分。
- 运行手册和操作手册: 为常见故障准备预先编写的指南。如果数据库锁定,工程师不应该需要上网搜索“如何解锁数据库”。
- 无责后期分析: 关注流程改进,而不是个人。如果工程师害怕惩罚,他们可能会隐瞒故障,从而使MTTR指标不准确。
相关术语
- MTTD(平均检测时间)
- MTBF(平均故障间隔时间)
- SLA(服务水平协议)
- 事件管理
常见误区
-
误区:可以达到“零漏洞”。
现实:目标是足够快地修复关键问题以防止被利用。
-
误区:更多扫描器意味着更好的安全性。
实际上,如果不进行集成,添加工具只会产生更多噪音和手动工作。
-
误区:安全工具会拖慢开发人员的速度。
现实:只有当安全工具生成“错误”警报时才会拖慢开发人员。当您提供预先编写的拉取请求时,实际上是在为他们节省数小时的研究时间。
常见问题
什么是“良好”的MTTR?
顶级DevOps团队的目标是将关键漏洞的MTTR控制在24小时以内。
MTTR与MTTD有何不同?
MTTD(平均检测时间)显示威胁存在多长时间后您才注意到它。MTTR显示在您发现它之后它还会存在多长时间。
AI真的能帮助MTTR吗?
是的。像Plexicus这样的AI工具可以处理分诊并建议修复方案,这通常占补救过程的80%。
最后的想法
MTTR是您安全计划的心跳。如果它很高,您的风险也很高。通过自动化从发现问题到创建拉取请求的过渡,您不再将安全视为瓶颈,而是将其视为CI/CD管道的正常部分。