Gennemsnitlig Tid til Afhjælpning (MTTR)
TL;DR
- MTTR repræsenterer den gennemsnitlige tid, der kræves for at løse en sikkerhedssårbarhed efter identifikation, hvilket giver et direkte mål for operationel effektivitet.
- For at beregne MTTR, divider den samlede tid brugt på at løse problemer med antallet af hændelser.
- Målet er at minimere eksponeringstiden, så angribere er mindre tilbøjelige til at udnytte kendte huller.
- Løsningen er at accelerere processen ved at automatisere alt fra sårbarhedsdetektion til kodefixgenerering, eliminere forsinkelser i manuelle billetkøer og sikre hurtigere afhjælpning.
Hvad er MTTR?
Gennemsnitlig Tid til Afhjælpning (MTTR) er en vigtig cybersikkerhedsmetrik, der viser, hvor hurtigt du reagerer på en kendt trussel. Den måler tiden fra, når en sårbarhed opdages, til når en løsning implementeres.
Mens metrikker som MTTD afspejler detektionshastighed, afslører MTTR din organisations reelle afhjælpningseffektivitet. Hurtig detektion skal matches med hurtig løsning for at begrænse risikoudsættelse og understøtte forretningskontinuitet.
Hvorfor MTTR er Vigtigt
Cyberkriminelle opererer hurtigere end traditionelle udviklingstidslinjer, hvilket øger behovet for responsive sikkerhedsoperationer. Industrielle tendenser indikerer, at forsvarsvinduerne bliver mindre.
- Det 5-dages udnyttelsesvindue: I 2025 faldt den gennemsnitlige Time to Exploit (TTE), tidsrummet mellem hvornår en sårbarhed bliver offentliggjort og hvornår den aktivt udnyttes, fra 32 dage til blot 5 dage (CyberMindr, 2025).
- Eksploitationsbølge: Brug af sårbarheder som indgangsvej er steget med 34% i år og forårsager nu 20% af alle bekræftede brud.
- Forsinkelse i afhjælpning: Angribere handler inden for dage, men organisationer tager ofte uger. Den mediane tid til at rette kritiske sårbarheder i edge- og VPN-enheder forbliver 32 dage, hvilket efterlader et betydeligt risikovindue. Kun 54% af fejlene bliver nogensinde fuldt ud rettet (Verizon DBIR, 2025). Dag Acceleration: Opdagelsen af udnyttede zero-day sårbarheder steg med 46% sammenlignet med sidste år. Angribere våbenfører nu disse fejl inden for timer efter identifikation (WithSecure Labs, 2025).
- Høj MTTR øger forretningsomkostningerne langt ud over teknisk gæld. I 2025 er de gennemsnitlige omkostninger ved et amerikansk databrud $4,4 millioner, hovedsageligt på grund af forsinket respons og regulatoriske sanktioner (IBM, 2025).
- Overholdelsesstraffe: Under regler som DORA tæller lange eksponeringstider som fejl under operationel modstandsdygtighed. Organisationer med høj MTTR står nu over for obligatorisk rapportering og store bøder for manglende overholdelse. Du kan ikke bevæge dig hurtigere end udnyttelsesscripts; dit forsvar er rent teoretisk.
Hvordan man beregner MTTR
MTTR beregnes ved at dividere den samlede tid brugt på at reparere et system med antallet af reparationer udført over en specifik periode.
Formlen
{kind=link}
Beregningseksempel
Forestil dig, at dit ingeniørteam håndterede 4 hændelser sidste måned:
- Hændelse A: Databaseudfald (Løst på 30 minutter)
- Hændelse B: API-fejl (Løst på 2 timer / 120 minutter)
- Hændelse C: Cache-fejl (Løst på 15 minutter)
- Hændelse D: Sikkerhedspatch (Løst på 45 minutter)
- Samlet reparationstid: 30 + 120 + 15 + 45 = 210 minutter
- Antal reparationer: 4
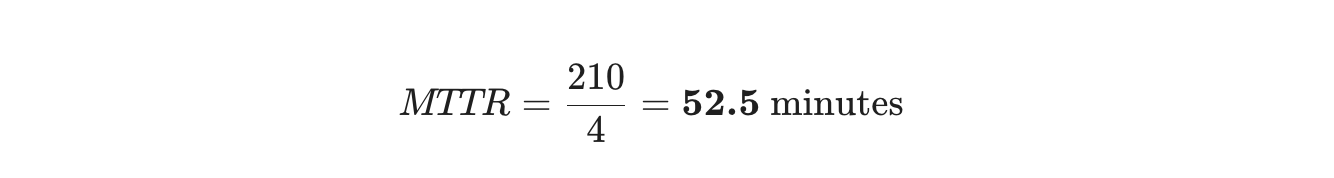{kind=link}
Dette betyder, at det i gennemsnit tager dit team cirka 52 minutter at løse et problem, når de først begynder at arbejde på det.
Eksempel i praksis
Overvej to virksomheder, der står over for en kritisk sikkerhedssårbarhed (f.eks. Log4Shell).
Virksomhed A (Høj MTTR):
- Proces: Manuel. Advarsler går til e-mail. En ingeniør skal manuelt SSH ind på servere for at finde de sårbare jar-filer og patche dem én efter én.
- MTTR: 48 timer.
- Resultat: Angribere har to hele dage til at udnytte sårbarheden. Data er sandsynligvis kompromitteret.
Virksomhed B (Lav MTTR - bruger Plexicus til at automatisere afhjælpning):
- Proces: Automatiseret. Sårbarheden opdages med det samme. En automatiseret playbook udløses for at isolere de berørte containere og anvende en patch eller virtuel firewallregel.
- MTTR: 15 Minutter.
- Resultat: Sårbarheden lukkes, før angribere kan iværksætte et vellykket angreb.
Hvem Bruger MTTR
- DevOps Ingeniører - For at spore effektiviteten af deres deployment- og rollback-pipelines.
- SREs (Site Reliability Engineers) - Sikrer, at de opfylder SLA’er (Service Level Agreements) for oppetid.
- SOC Analytikere - For at måle, hvor hurtigt de kan neutralisere aktive sikkerhedstrusler.
- CTO’er & CISO’er - For at retfærdiggøre investeringer i automatiseringsværktøjer ved at vise en reduktion i genopretningstid.
Hvornår Skal MTTR Anvendes
MTTR bør overvåges kontinuerligt, men det er mest kritisk under Incident Response-fasen af SDLC (Software Development Life Cycle)
- Under Hændelser: Det fungerer som en live pulscheck. “Løser vi dette hurtigt nok?”
- Post-Mortem: Efter en hændelse hjælper det at gennemgå MTTR med at identificere, om forsinkelsen skyldtes opdagelsen af problemet (MTTD) eller løsningen af det (MTTR).
- SLA Forhandling: Du kan ikke love en kunde “99,99% oppetid”, hvis din gennemsnitlige MTTR er 4 timer.
Bedste Praksis for at Reducere MTTR
- Automatiser alt: Manuelle rettelser er langsomme og fejlbehæftede. Brug Infrastructure as Code (IaC) til at genudrulle ødelagt infrastruktur i stedet for at rette det manuelt.
- Bedre overvågning: Du kan ikke rette, hvad du ikke kan se. Granulære observabilitetsværktøjer hjælper med at lokalisere roden til problemet hurtigere, hvilket reducerer “diagnose”-delen af reparationstiden.
- Runbooks & Playbooks: Hav forudskrevne guider til almindelige fejl. Hvis en database låser, skal ingeniøren ikke skulle Google “hvordan man låser en database op.”
- Skyldfri post-mortems: Fokusér på procesforbedring, ikke mennesker. Hvis ingeniører frygter straf, kan de skjule fejl, hvilket gør MTTR-metrikker unøjagtige.
Relaterede termer
- MTTD (Mean Time To Detect)
- MTBF (Mean Time Between Failures)
- SLA (Service Level Agreement)
- Hændelseshåndtering
Almindelige myter
-
Myte: Du kan nå “nul sårbarheder.”
Virkelighed: Målet er at rette kritiske problemer hurtigt nok til at slå udnyttelse.
-
Myte: Flere scannere giver bedre sikkerhed.
I virkeligheden skaber tilføjelse af værktøjer blot mere støj og manuelt arbejde, hvis de ikke er integreret.
-
Myte: Sikkerhedsværktøjer bremser udviklere.
Virkelighed: Sikkerhed bremser kun udviklere, når det genererer “ødelagte” alarmer. Når du leverer en forudskrevet pull request, sparer du dem timer med research.
FAQ
Hvad er en “god” MTTR?
Top DevOps-teams sigter efter en MTTR på under 24 timer for kritiske sårbarheder.
Hvordan adskiller MTTR sig fra MTTD?
MTTD (Mean Time to Detect) viser, hvor længe en trussel er til stede, før du opdager den. MTTR viser, hvor længe den forbliver, efter du har fundet den.
Kan AI faktisk hjælpe med MTTR?
Ja. AI-værktøjer som Plexicus håndterer triage og foreslår løsninger, hvilket typisk udgør 80% af afhjælpningsprocessen.
Afsluttende tanke
MTTR er hjerteslaget i dit sikkerhedsprogram. Hvis det er højt, er din risiko høj. Ved at automatisere overgangen fra at finde problemer til at oprette pull requests, stopper du med at behandle sikkerhed som en flaskehals og begynder at behandle det som en normal del af din CI/CD-pipeline.