Mean Time to Remediation (MTTR)
TL;DR
- MTTR repräsentiert die durchschnittliche Zeit, die benötigt wird, um eine Sicherheitslücke nach ihrer Identifizierung zu beheben, und bietet ein direktes Maß für die betriebliche Effizienz.
- Um MTTR zu berechnen, teilen Sie die gesamte Zeit, die für die Behebung von Problemen aufgewendet wurde, durch die Anzahl der Vorfälle.
- Das Ziel ist es, die Expositionszeit zu minimieren, damit Angreifer weniger wahrscheinlich bekannte Lücken ausnutzen können.
- Die Lösung besteht darin, den Prozess zu beschleunigen, indem alles von der Erkennung von Schwachstellen bis zur Generierung von Code-Fixes automatisiert wird, Verzögerungen in manuellen Ticket-Warteschlangen beseitigt werden und eine schnellere Behebung sichergestellt wird.
Was ist MTTR?
Mean Time to Remediation (MTTR) ist eine wichtige Kennzahl in der Cybersicherheit, die zeigt, wie schnell Sie auf eine bekannte Bedrohung reagieren. Sie misst die Zeit von der Entdeckung einer Schwachstelle bis zur Implementierung einer Lösung.
Während Kennzahlen wie MTTD die Erkennungsgeschwindigkeit widerspiegeln, zeigt MTTR die tatsächliche Effizienz Ihrer Organisation bei der Behebung auf. Eine schnelle Erkennung muss mit einer zügigen Lösung einhergehen, um das Risiko zu begrenzen und die Geschäftskontinuität zu unterstützen.
Warum MTTR wichtig ist
Cyberkriminelle agieren schneller als traditionelle Entwicklungszeitpläne, was die Nachfrage nach reaktionsfähigen Sicherheitsoperationen beschleunigt. Branchentrends zeigen, dass sich die Verteidigungsfenster verkleinern.
- Das 5-Tage-Exploit-Fenster: Im Jahr 2025 fiel die durchschnittliche Time to Exploit (TTE), die Lücke zwischen der Veröffentlichung einer Schwachstelle und ihrer aktiven Ausnutzung, von 32 Tagen auf nur 5 Tage (CyberMindr, 2025).
- Anstieg der Ausnutzung: Die Nutzung von Schwachstellen als Einstiegspunkt ist in diesem Jahr um 34 % gestiegen und verursacht nun 20 % aller bestätigten Sicherheitsverletzungen.
- Das Behebungsdefizit: Angreifer handeln in Tagen, aber Organisationen benötigen oft Wochen. Die mittlere Zeit zur Behebung kritischer Schwachstellen in Edge- und VPN-Geräten bleibt bei 32 Tagen, was ein erhebliches Risikofenster hinterlässt. Nur 54 % der Schwachstellen werden jemals vollständig gepatcht (Verizon DBIR, 2025). Tagesbeschleunigung: Die Entdeckung ausgenutzter Zero-Day-Schwachstellen stieg im Vergleich zum Vorjahr um 46 %. Angreifer nutzen diese Schwachstellen nun innerhalb von Stunden nach ihrer Identifizierung aus (WithSecure Labs, 2025).
- Hohe MTTR treibt die Geschäftskosten weit über die technische Verschuldung hinaus. Im Jahr 2025 betragen die durchschnittlichen Kosten eines Datenlecks in den USA 4,4 Millionen Dollar, hauptsächlich aufgrund verzögerter Reaktionen und regulatorischer Strafen (IBM, 2025).
- Compliance-Strafen: Unter Regeln wie DORA gelten lange Expositionszeiten als Versagen in der operativen Resilienz. Organisationen mit hoher MTTR stehen nun vor einer verpflichtenden Berichterstattung und hohen Strafen bei Nichteinhaltung. Sie können nicht schneller agieren als die Exploit-Skripte; Ihre Verteidigung ist rein theoretisch.
Wie man MTTR berechnet
MTTR wird berechnet, indem die gesamte Zeit, die für die Reparatur eines Systems aufgewendet wird, durch die Anzahl der in einem bestimmten Zeitraum durchgeführten Reparaturen geteilt wird.
Die Formel
{kind=link}
Berechnungsbeispiel
Stellen Sie sich vor, Ihr Ingenieurteam hat letzten Monat 4 Vorfälle bearbeitet:
- Vorfall A: Datenbankausfall (Behoben in 30 Minuten)
- Vorfall B: API-Ausfall (Behoben in 2 Stunden / 120 Minuten)
- Vorfall C: Cache-Fehler (Behoben in 15 Minuten)
- Vorfall D: Sicherheitspatch (Behoben in 45 Minuten)
- Gesamte Reparaturzeit: 30 + 120 + 15 + 45 = 210 Minuten
- Anzahl der Reparaturen: 4
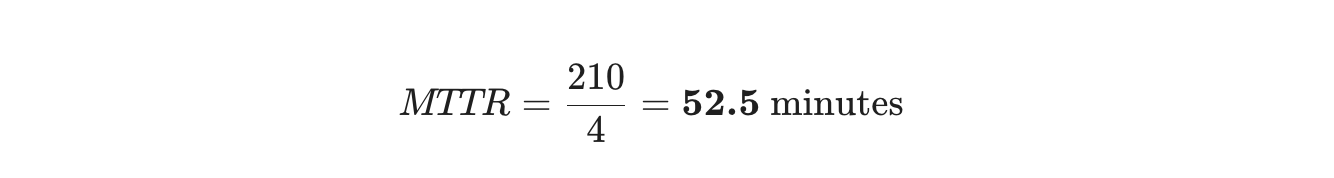{kind=link}
Das bedeutet, dass Ihr Team im Durchschnitt etwa 52 Minuten benötigt, um ein Problem zu beheben, sobald sie damit beginnen.
Beispiel in der Praxis
Betrachten Sie zwei Unternehmen, die mit einer kritischen Sicherheitslücke konfrontiert sind (z.B. Log4Shell).
Unternehmen A (Hohe MTTR):
- Prozess: Manuell. Warnungen gehen per E-Mail ein. Ein Ingenieur muss sich manuell per SSH auf Servern einloggen, um die anfälligen Jar-Dateien zu finden und sie einzeln zu patchen.
- MTTR: 48 Stunden.
- Ergebnis: Angreifer haben zwei volle Tage Zeit, die Sicherheitslücke auszunutzen. Daten sind wahrscheinlich kompromittiert.
Unternehmen B (Niedrige MTTR - mit Plexicus zur Automatisierung der Behebung):
- Prozess: Automatisiert. Die Schwachstelle wird sofort erkannt. Ein automatisiertes Playbook wird ausgelöst, um betroffene Container zu isolieren und einen Patch oder eine virtuelle Firewall-Regel anzuwenden.
- MTTR: 15 Minuten.
- Ergebnis: Die Schwachstelle wird geschlossen, bevor Angreifer einen erfolgreichen Exploit starten können.
Wer verwendet MTTR
- DevOps-Ingenieure - Um die Effizienz ihrer Bereitstellungs- und Rollback-Pipelines zu verfolgen.
- SREs (Site Reliability Engineers) - Sicherstellen, dass sie die SLAs (Service Level Agreements) für die Betriebszeit einhalten.
- SOC-Analysten - Um zu messen, wie schnell sie aktive Sicherheitsbedrohungen neutralisieren können.
- CTOs & CISOs - Um Investitionen in Automatisierungstools zu rechtfertigen, indem sie eine Reduzierung der Wiederherstellungszeit zeigen.
Wann MTTR angewendet werden sollte
MTTR sollte kontinuierlich überwacht werden, ist jedoch während der Incident Response-Phase des SDLC (Software Development Life Cycle) am kritischsten.
- Während Vorfällen: Es dient als Live-Puls-Check. “Beheben wir das schnell genug?”
- Post-Mortem: Nach einem Vorfall hilft die Überprüfung von MTTR zu identifizieren, ob die Verzögerung durch das Erkennen des Problems (MTTD) oder das Beheben (MTTR) verursacht wurde.
- SLA-Verhandlung: Sie können einem Kunden keine “99,99% Betriebszeit” versprechen, wenn Ihre durchschnittliche MTTR 4 Stunden beträgt.
Best Practices zur Reduzierung von MTTR
- Alles automatisieren: Manuelle Korrekturen sind langsam und fehleranfällig. Verwenden Sie Infrastructure as Code (IaC), um defekte Infrastruktur neu bereitzustellen, anstatt sie manuell zu reparieren.
- Bessere Überwachung: Sie können nicht beheben, was Sie nicht sehen können. Granulare Beobachtungstools helfen, die Ursache schneller zu identifizieren und reduzieren die “Diagnose”-Zeit bei Reparaturen.
- Runbooks & Playbooks: Haben Sie vorgefertigte Anleitungen für häufige Ausfälle. Wenn eine Datenbank blockiert, sollte der Ingenieur nicht “wie man eine Datenbank entsperrt” googeln müssen.
- Blameless Post-Mortems: Konzentrieren Sie sich auf die Prozess-Verbesserung, nicht auf Personen. Wenn Ingenieure Angst vor Bestrafung haben, könnten sie Fehler verbergen, was die MTTR-Metriken ungenau macht.
Verwandte Begriffe
- MTTD (Mean Time To Detect)
- MTBF (Mean Time Between Failures)
- SLA (Service Level Agreement)
- Incident Management
Häufige Mythen
-
Mythos: Man kann “null Schwachstellen” erreichen.
Realität: Das Ziel ist es, kritische Probleme schnell genug zu beheben, um einer Ausnutzung zuvorzukommen.
-
Mythos: Mehr Scanner bedeuten bessere Sicherheit.
In Wirklichkeit erzeugt das Hinzufügen von Tools nur mehr Lärm und manuelle Arbeit, wenn sie nicht integriert sind.
-
Mythos: Sicherheitstools verlangsamen Entwickler.
Realität: Sicherheit verlangsamt Entwickler nur, wenn sie “fehlerhafte” Warnungen erzeugt. Wenn Sie einen vorgefertigten Pull-Request bereitstellen, sparen Sie ihnen Stunden an Recherche.
FAQ
Was ist ein “gutes” MTTR?
Top-DevOps-Teams streben ein MTTR von unter 24 Stunden für kritische Schwachstellen an.
Wie unterscheidet sich MTTR von MTTD?
MTTD (Mean Time to Detect) zeigt, wie lange eine Bedrohung vorhanden ist, bevor Sie sie bemerken. MTTR zeigt, wie lange sie bleibt, nachdem Sie sie gefunden haben.
Kann KI tatsächlich bei MTTR helfen?
Ja. KI-Tools wie Plexicus übernehmen die Ersteinschätzung und schlagen Lösungen vor, die typischerweise 80 % des Behebungsprozesses ausmachen.
Abschließender Gedanke
MTTR ist der Herzschlag Ihres Sicherheitsprogramms. Wenn es hoch ist, ist Ihr Risiko hoch. Indem Sie den Übergang vom Finden von Problemen zum Erstellen von Pull-Requests automatisieren, hören Sie auf, Sicherheit als Engpass zu behandeln, und beginnen, sie als normalen Teil Ihrer CI/CD-Pipeline zu betrachten.