Średni Czas na Usunięcie Zagrożenia (MTTR)
TL;DR
- MTTR reprezentuje średni czas potrzebny na rozwiązanie problemu związanego z bezpieczeństwem po jego zidentyfikowaniu, co stanowi bezpośredni miernik efektywności operacyjnej.
- Aby obliczyć MTTR, podziel całkowity czas poświęcony na naprawę problemów przez liczbę incydentów.
- Celem jest zminimalizowanie czasu ekspozycji, aby zmniejszyć prawdopodobieństwo wykorzystania znanych luk przez atakujących.
- Rozwiązaniem jest przyspieszenie procesu poprzez automatyzację wszystkiego, od wykrywania luk po generowanie poprawek kodu, eliminując opóźnienia w ręcznych kolejkach zgłoszeń i zapewniając szybsze usuwanie zagrożeń.
Co to jest MTTR?
Średni Czas na Usunięcie Zagrożenia (MTTR) to kluczowy wskaźnik w dziedzinie cyberbezpieczeństwa, który pokazuje, jak szybko reagujesz na znane zagrożenie. Mierzy czas od momentu wykrycia luki do momentu wdrożenia poprawki.
Podczas gdy wskaźniki takie jak MTTD odzwierciedlają szybkość wykrywania, MTTR ujawnia rzeczywistą efektywność usuwania zagrożeń w Twojej organizacji. Szybkie wykrywanie musi być uzupełnione szybką reakcją, aby ograniczyć ryzyko i wspierać ciągłość działania biznesu.
Dlaczego MTTR jest ważny
Cyberprzestępcy działają szybciej niż tradycyjne harmonogramy rozwoju, co zwiększa zapotrzebowanie na responsywne operacje bezpieczeństwa. Trendy w branży wskazują, że okna obronne się kurczą.
- 5-dniowe okno eksploatacji: W 2025 roku średni czas do eksploatacji (TTE), czyli okres między ujawnieniem podatności a jej aktywnym wykorzystaniem, spadł z 32 dni do zaledwie 5 dni (CyberMindr, 2025).
- Wzrost eksploatacji: Wykorzystanie podatności jako drogi wejścia wzrosło o 34% w tym roku i teraz powoduje 20% wszystkich potwierdzonych naruszeń.
- Opóźnienie w naprawie: Atakujący działają w ciągu dni, ale organizacje często potrzebują tygodni. Mediana czasu na naprawę krytycznych podatności w urządzeniach brzegowych i VPN wynosi 32 dni, co pozostawia znaczące okno ryzyka. Tylko 54% wad jest kiedykolwiek w pełni załatanych (Verizon DBIR, 2025). Przyspieszenie dnia: Odkrycie wykorzystywanych podatności zero-day wzrosło o 46% w porównaniu do zeszłego roku. Atakujący teraz uzbrajają te wady w ciągu godzin od ich identyfikacji (WithSecure Labs, 2025).
- Wysoki MTTR zwiększa koszty biznesowe znacznie poza dług techniczny. W 2025 roku średni koszt naruszenia danych w USA wynosi 4,4 miliona dolarów, głównie z powodu opóźnionej reakcji i kar regulacyjnych (IBM, 2025).
- Kary za niezgodność: Zgodnie z przepisami takimi jak DORA, długie czasy ekspozycji są traktowane jako niepowodzenia w zakresie odporności operacyjnej. Organizacje z wysokim MTTR teraz muszą zgłaszać obowiązkowo i ponoszą duże kary za niezgodność. Nie można działać szybciej niż skrypty eksploatacyjne; twoja obrona jest czysto teoretyczna.
Jak obliczyć MTTR
MTTR jest obliczany poprzez podzielenie całkowitego czasu spędzonego na naprawie systemu przez liczbę napraw wykonanych w określonym okresie.
Wzór
{kind=link}
Przykład obliczenia
Wyobraź sobie, że twój zespół inżynierów obsłużył 4 incydenty w zeszłym miesiącu:
- Incydent A: Awaria bazy danych (Naprawiono w 30 minut)
- Incydent B: Awaria API (Naprawiono w 2 godziny / 120 minut)
- Incydent C: Błąd pamięci podręcznej (Naprawiono w 15 minut)
- Incydent D: Łatka bezpieczeństwa (Naprawiono w 45 minut)
- Całkowity czas naprawy: 30 + 120 + 15 + 45 = 210 minut
- Liczba napraw: 4
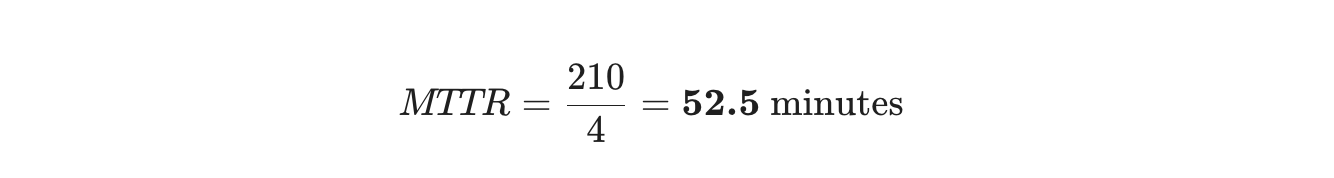{kind=link}
To oznacza, że średnio twój zespół potrzebuje około 52 minut na naprawienie problemu od momentu rozpoczęcia pracy nad nim.
Przykład w praktyce
Rozważmy dwie firmy stające w obliczu krytycznej luki w zabezpieczeniach (np. Log4Shell).
Firma A (wysoki MTTR):
- Proces: Ręczny. Alerty trafiają na e-mail. Inżynier musi ręcznie zalogować się na serwery przez SSH, aby znaleźć podatne pliki jar i załatać je jeden po drugim.
- MTTR: 48 godzin.
- Wynik: Atakujący mają pełne dwa dni na wykorzystanie luki. Dane prawdopodobnie zostały skompromitowane.
Firma B (niski MTTR - używająca Plexicus do automatyzacji napraw):
- Proces: Zautomatyzowany. Wykrycie podatności następuje natychmiast. Automatyczny playbook uruchamia się, aby odizolować dotknięte kontenery i zastosować poprawkę lub wirtualną regułę zapory.
- MTTR: 15 minut.
- Wynik: Podatność zostaje zamknięta, zanim atakujący mogą przeprowadzić skuteczny atak.
Kto używa MTTR
- Inżynierowie DevOps - Aby śledzić efektywność swoich procesów wdrażania i wycofywania.
- SRE (Site Reliability Engineers) - Aby zapewnić spełnienie SLA (Service Level Agreements) dotyczących dostępności.
- Analitycy SOC - Aby mierzyć, jak szybko mogą zneutralizować aktywne zagrożenia bezpieczeństwa.
- CTO i CISO - Aby uzasadnić inwestycje w narzędzia automatyzacji, pokazując skrócenie czasu odzyskiwania.
Kiedy stosować MTTR
MTTR powinien być monitorowany na bieżąco, ale jest najważniejszy podczas fazy Reagowania na incydenty w SDLC (Cykl Życia Oprogramowania)
- Podczas incydentów: Działa jako bieżący wskaźnik. “Czy naprawiamy to wystarczająco szybko?”
- Post-Mortem: Po incydencie, przegląd MTTR pomaga zidentyfikować, czy opóźnienie było spowodowane wykryciem problemu (MTTD) czy naprawą go (MTTR).
- Negocjacje SLA: Nie można obiecać klientowi “99,99% dostępności”, jeśli średni MTTR wynosi 4 godziny.
Najlepsze praktyki redukcji MTTR
- Automatyzuj wszystko: Ręczne poprawki są powolne i podatne na błędy. Użyj Infrastructure as Code (IaC), aby ponownie wdrożyć uszkodzoną infrastrukturę zamiast naprawiać ją ręcznie.
- Lepsze monitorowanie: Nie możesz naprawić tego, czego nie widzisz. Narzędzia do szczegółowej obserwowalności pomagają szybciej zlokalizować przyczynę problemu, skracając czas „diagnozy” podczas naprawy.
- Runbooki i playbooki: Miej przygotowane przewodniki na wypadek typowych awarii. Jeśli baza danych się zablokuje, inżynier nie powinien musieć szukać w Google „jak odblokować bazę danych”.
- Bezwinne post-mortemy: Skup się na poprawie procesu, a nie ludzi. Jeśli inżynierowie boją się kary, mogą ukrywać awarie, co sprawia, że metryki MTTR są niedokładne.
Powiązane terminy
- MTTD (Średni czas wykrycia)
- MTBF (Średni czas między awariami)
- SLA (Umowa o poziomie usług)
- Zarządzanie incydentami
Powszechne mity
-
Mit: Możesz osiągnąć „zero podatności”.
Rzeczywistość: Celem jest naprawa krytycznych problemów wystarczająco szybko, aby zapobiec ich wykorzystaniu.
-
Mit: Więcej skanerów oznacza lepsze bezpieczeństwo.
W rzeczywistości dodawanie narzędzi tworzy tylko więcej szumu i pracy ręcznej, jeśli nie są zintegrowane.
-
Mit: Narzędzia bezpieczeństwa spowalniają deweloperów.
Rzeczywistość: Bezpieczeństwo spowalnia deweloperów tylko wtedy, gdy generuje „błędne” alerty. Kiedy dostarczasz gotowy pull request, oszczędzasz im godziny badań.
FAQ
Co to jest „dobry” MTTR?
Najlepsze zespoły DevOps dążą do MTTR poniżej 24 godzin dla krytycznych podatności.
Jak MTTR różni się od MTTD?
MTTD (Średni Czas Wykrycia) pokazuje, jak długo zagrożenie jest obecne, zanim je zauważysz. MTTR pokazuje, jak długo pozostaje po jego wykryciu.
Czy AI może rzeczywiście pomóc w MTTR?
Tak. Narzędzia AI, takie jak Plexicus, zajmują się triage i sugerują poprawki, co zazwyczaj stanowi 80% procesu naprawczego.
Ostateczna Myśl
MTTR jest sercem twojego programu bezpieczeństwa. Jeśli jest wysoki, twoje ryzyko jest wysokie. Automatyzując przejście od znajdowania problemów do tworzenia pull requestów, przestajesz traktować bezpieczeństwo jako wąskie gardło i zaczynasz traktować je jako normalną część swojego pipeline’u CI/CD.