Alarmtræthed
TL;DR
Alarmtræthed opstår, når teams modtager så mange notifikationer, at de holder op med at være opmærksomme på dem.
Hvad er Alarmtræthed?
Alarmtræthed er det, der sker, når sikkerheds- eller operationsteams oversvømmes med alarmer hver dag. Over tid bliver folk trætte, stressede og begynder at ignorere dem.
Inden for sikkerhed kommer dette normalt fra værktøjer, der alarmerer om alt, reelle problemer, små problemer og ting, der slet ikke er problemer.
Når hver alarm føles kritisk, føles ingen af dem virkelig presserende længere. Hjernen lærer at ignorere dem, ligesom en alarm, der går for ofte.
Hvorfor Alarmtræthed er Farligt
Alarmtræthed er ikke bare irriterende. Det er risikabelt.
Mange store sikkerhedsbrud skete, selvom alarmer blev udløst. Problemet var, at ingen bemærkede eller reagerede i tide.
Hovedrisici:
1. Reelle trusler bliver ignoreret.
Når de fleste alarmer er falske alarmer, ser reelle angreb ens ud og bliver overset.
2. Langsom respons
Tid brugt på at gennemgå unyttige alarmer er tid, der ikke bruges på at løse reelle problemer.
3. Menneskelige fejl
Trætte teams laver fejl, springer trin over eller vurderer risiko forkert.
Hvorfor Alarmtræthed Opstår
Alarmtræthed kommer normalt fra en blanding af dårlige værktøjer og dårlig opsætning.
Almindelige årsager:
- For mange falske positiver
- Værktøjer markerer mulige problemer uden at kontrollere, om de faktisk kan udnyttes.
- Ingen reel prioritering
- Alt får samme alvorlighed, selv når risikoen er meget forskellig.
- Duplikerede alarmer
- Flere værktøjer rapporterer det samme problem på forskellige måder.
- Stive regler
- Alarmer udløses baseret på faste grænser i stedet for reel adfærd.
Hvordan man reducerer alarmtræthed
Den eneste reelle løsning er at reducere støj og fokusere på det, der betyder noget.
Fokus på reel risiko
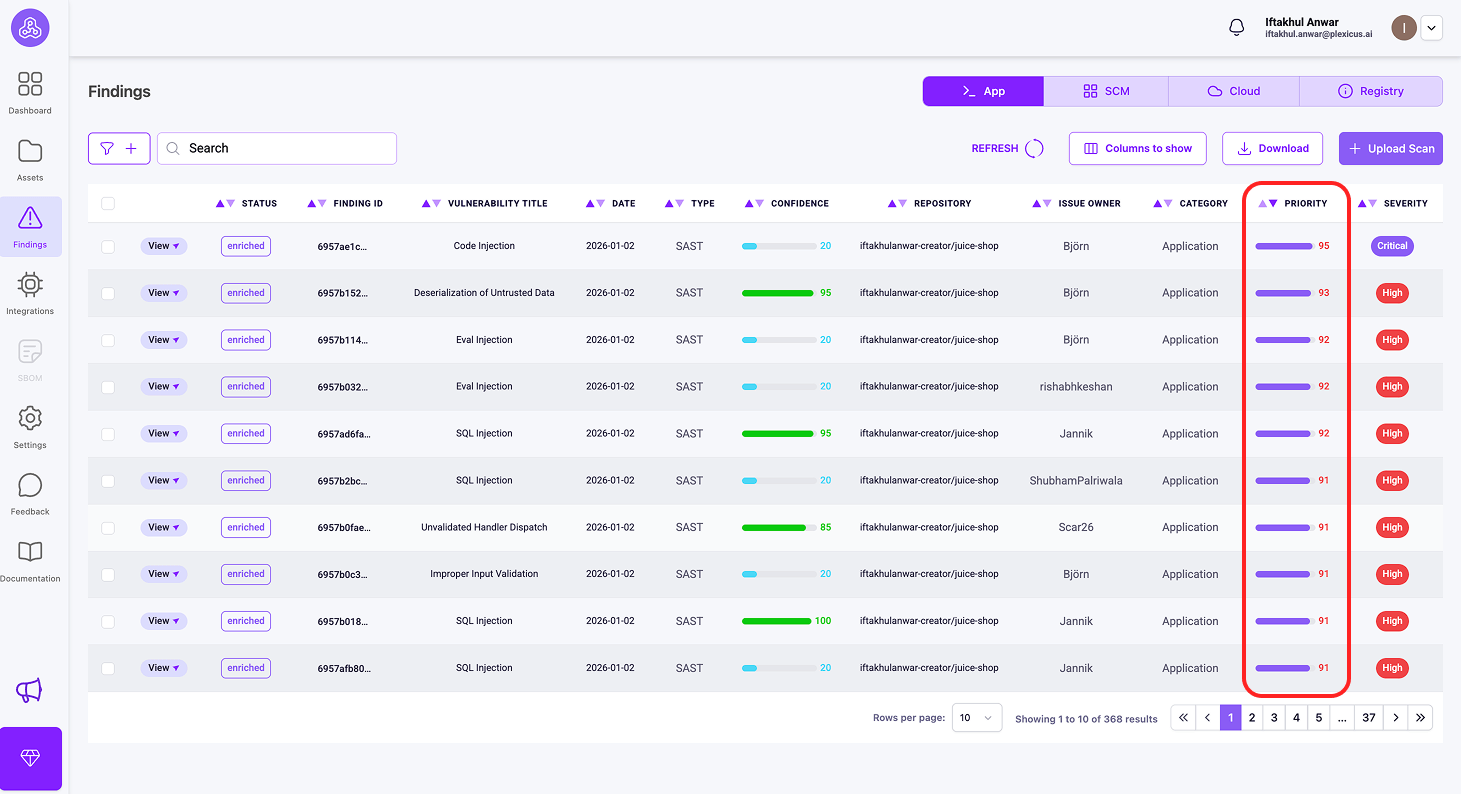
Ikke alle problemer er ens. Plexicus giver nogle metrics til at hjælpe dig med at prioritere sårbarheder:
1) Prioritetsmetrics
Hvad det måler: Overordnet hastende behov for afhjælpning
Det er en score (0-100), der kombinerer teknisk alvorlighed (CVSSv4), forretningspåvirkning og udnyttelsesmulighed til ét tal. Det er din handlingskø - sorter efter Prioritet for at vide, hvad der skal tackles med det samme. Prioritet 85 betyder “drop alt og fix dette nu”, mens Prioritet 45 betyder “planlæg det til næste sprint.”
Eksempel: SQL-injektion i et internt produktivitetsværktøj, kun tilgængeligt fra virksomhedens VPN, indeholder ikke følsomme data
- CVSSv4: 8.2 (høj teknisk alvorlighed)
- Forretningspåvirkning: 45 (internt værktøj, begrænset dataeksponering)
- Udnyttelsesmulighed: 30 (kræver godkendt adgang)
- Prioritet: 48
Hvorfor kigge efter prioritet: På trods af en høj CVSSv4 (8.2), nedgraderer Prioritet (48) korrekt hasten, fordi der er begrænset forretningspåvirkning og lav udnyttelsesgrad. Hvis du kun kiggede på CVSS, ville du unødigt gå i panik. Prioritet siger: “Planlæg dette til næste sprint,” med en score på omkring 45.
Dette gør anbefalingen om “næste sprint” meget mere rimelig - det er en reel sårbarhed, der skal løses, men ikke en nødsituation, fordi det er i et lavpåvirknings internt værktøj med begrænset eksponering.
2) Indvirkning
Hvad det måler: Forretningskonsekvenser
Indvirkning (0-100) evaluerer, hvad der sker, hvis sårbarheden udnyttes, under hensyntagen til din specifikke kontekst: datasensitivitet, systemkritikalitet, forretningsdrift og lovgivningsmæssig overholdelse.
Eksempel: SQL injection i en offentligt tilgængelig kundedatabase har Indvirkning 95, men den samme sårbarhed i et internt testmiljø har Indvirkning 30.
3) EPSS
Hvad det måler: Sandsynlighed for trussel i den virkelige verden
EPSS er en score (0.0-1.0), der forudsiger sandsynligheden for, at en specifik CVE vil blive udnyttet i naturen inden for de næste 30 dage
Eksempel: En 10 år gammel sårbarhed kan have CVSS 9.0 (meget alvorlig), men hvis ingen længere udnytter den, ville EPSS være lav (0.01). Omvendt kan en nyere CVE med CVSS 6.0 have EPSS 0.85, fordi angribere aktivt bruger den.
Du kan tjekke disse metrikker for prioritering ved at følge disse trin:
- Sørg for, at dit repository er forbundet, og at scanningsprocessen er afsluttet.
- Gå derefter til Findings-menuen, hvor du finder de metrikker, du har brug for til prioritering.
Vigtige Forskelle
| Metrik | Svar | Omfang | Rækkevidde |
|---|---|---|---|
| EPSS | “Bruger angribere dette?” | Globalt trusselslandskab | 0.0-1.0 |
| Prioritet | “Hvad skal jeg fikse først?” | Kombineret hastescore | 0-100 |
| Indvirkning | “Hvor slemt for MIN virksomhed?” | Organisationsspecifik | 0-100 |
Tilføj Kontekst
Hvis et sårbart bibliotek eksisterer, men din app aldrig bruger det, bør den advarsel ikke have høj prioritet.
Juster og Automatiser
Lær værktøjer over tid, hvad der er sikkert, og hvad der ikke er. Automatiser simple rettelser, så folk kun håndterer reelle trusler.
Brug Én Klar Visning
Ved at bruge en enkelt platform som Plexicus hjælper det med at fjerne duplikerede advarsler og viser kun, hvad der kræver handling.
Alarmtræthed i Virkeligheden
| Situation | Uden Støjkontrol | Med Smart Alarmering |
|---|---|---|
| Daglige alarmer | 1.000+ | 15–20 |
| Teamhumør | Overvældet | Fokuseret |
| Oversete risici | Almindelige | Sjældne |
| Mål | Klare alarmer | Løs reelle problemer |
Relaterede Termer
FAQ
Hvor mange alarmer er for mange?
De fleste mennesker kan kun korrekt gennemgå omkring 10-15 alarmer om dagen. Mere end det fører normalt til oversete problemer.
Er alarmtræthed kun et sikkerhedsproblem?
Nej. Det sker også inden for sundhedspleje, IT-drift og kundesupport. Inden for sikkerhed er påvirkningen værre, fordi oversete alarmer kan føre til alvorlige brud.
Gør det tingene værre at slukke for alarmer?
Hvis alarmer slukkes uden omtanke, ja.
Hvis alarmer reduceres baseret på reel risiko og kontekst, forbedres sikkerheden faktisk.