Hur man hindrar utvecklare från att ignorera säkerhetsfynd (och åtgärdar sårbarheter snabbare)

Säkerhetsverktyg har ett rykte om sig att vara bullriga hinder. När en utvecklare skickar in kod och CI/CD-pipelinen misslyckas med en 500-sidig PDF-rapport bifogad, är deras naturliga reaktion inte att åtgärda problemen. Det är att ignorera dem eller tvinga igenom koden.
Denna larmtrötthet är kvantifierbar. Branschdata visar att 33% av DevOps-team slösar mer än hälften av sin tid på att hantera falska positiva. Problemet är inte att utvecklare inte bryr sig om säkerhet. Problemet är att utvecklarupplevelsen (DevEx) av de flesta säkerhetsverktyg är trasig. De skannar för sent, ger för lite kontext och kräver för mycket manuell forskning.
Här är hur man löser arbetsflödesproblemet genom att flytta säkerheten in i CI/CD-pipelinen.
Varför Det Är Viktigt: “30-Minuters vs. 15-Timmars”-Regeln
Att ignorera säkerhetsfynd skapar en ackumulerande skuld som dödar hastigheten.
Data från NIST antyder att om en utvecklare åtgärdar en säkerhetsbrist under Pull Request (PR)-granskningen, tar det ungefär 30 minuter. Om samma brist upptäcks i efterproduktionstestning, tar det upp till 15 timmar att triagera, återlära sig kontexten och åtgärda.
När det gäller kostnader är det 30 gånger dyrare att åtgärda sårbarheter i post-produktion än under utvecklingsstadiet.
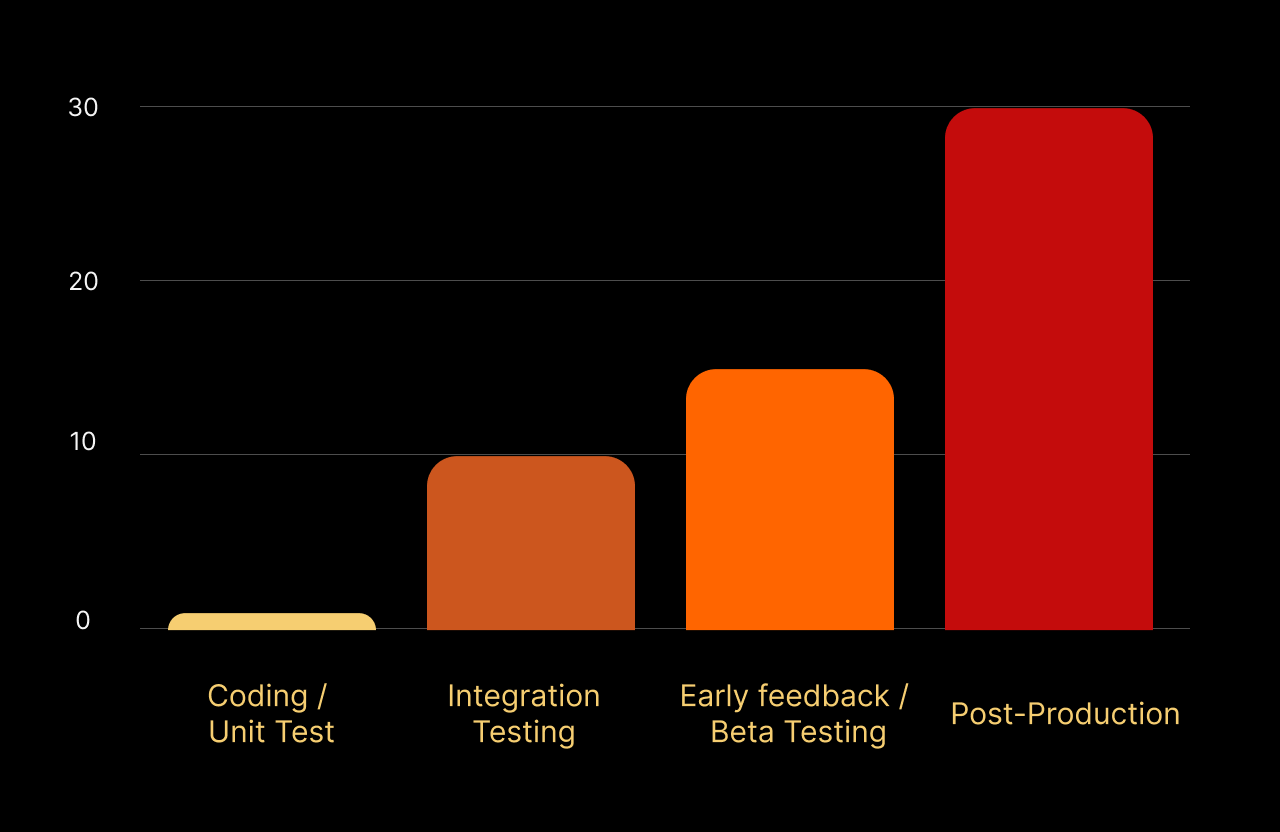
För ingenjörsledare är affärsfallet tydligt: Att förbättra säkerheten i DevEx handlar inte bara om säkerhet; det handlar om att återta 30% av ditt teams ingenjörskapacitet.
Hur man åtgärdar arbetsflödet
Målet är att gå från att “hitta buggar” till att “fixa buggar” utan att lämna Pull Request-gränssnittet.
Steg 1: Upptäck hemligheter och kodproblem
Äldre verktyg skannar ofta på natten. Vid det laget har utvecklaren bytt fokus till en ny uppgift. Du behöver flytta upptäckten till exakt det ögonblick då koden trycks till servern.
I Plexicus kan du integrera säkerhetsverktygen i CI/CD-pipelinen. Det kommer att skanna omedelbart vid en Pull Request. Det utför hemlighetsdetektion i din kod (Git) och statisk kodanalys (SAST).
Du kan integrera Plexicus i CI/CD-pipelinen genom att följa dessa steg.
Steg 2: Prioritering
Undvik larmtrötthet. Gör prioritering för säkerhetsproblem som hittas.
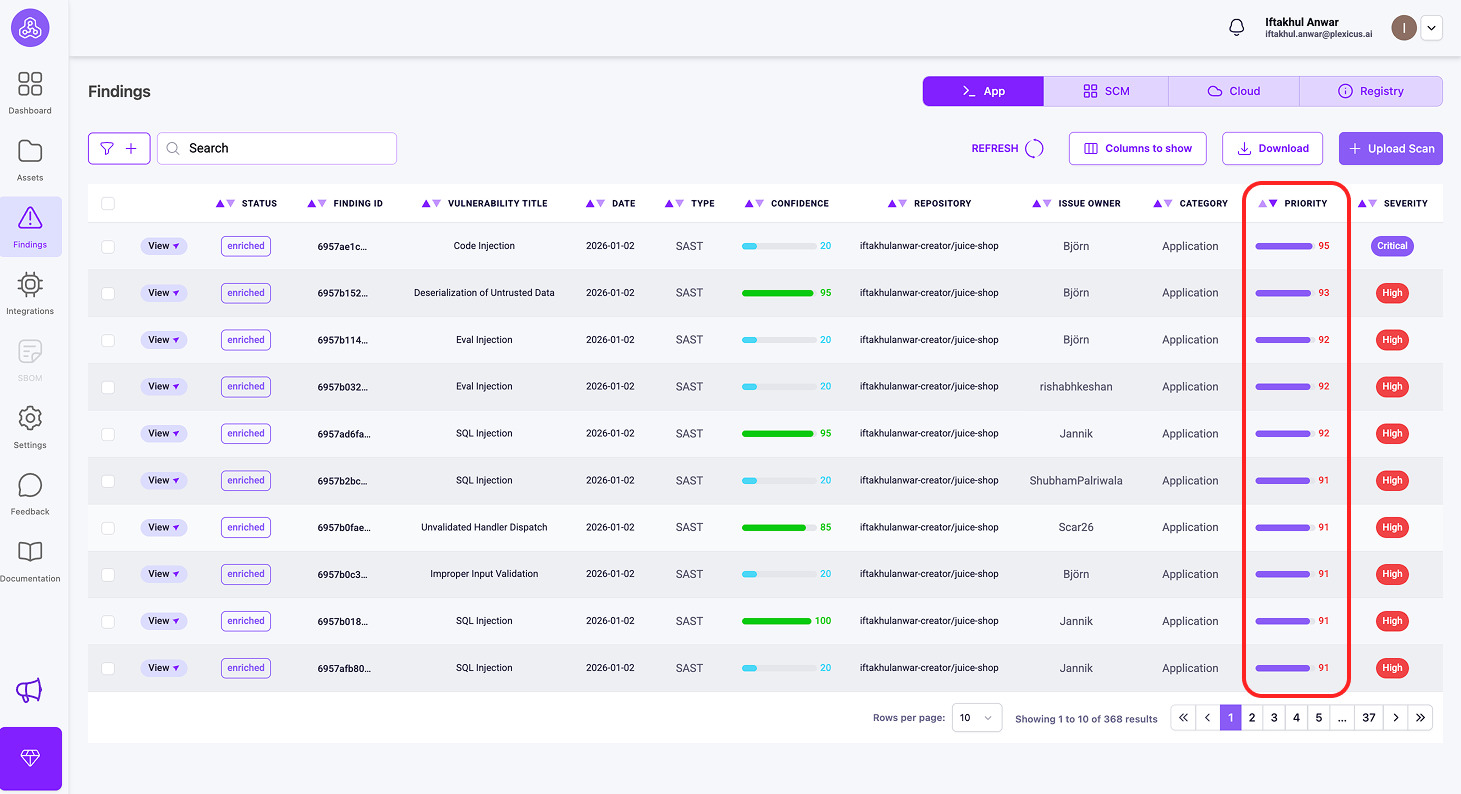
Plexicus erbjuder mätvärden för att hjälpa dig att bestämma vilka sårbarheter som ska åtgärdas först:
a) Prioritetsmätvärden
Vad det mäter: Hur brådskande det är att åtgärda problemet
Det är en poäng (0-100) som kombinerar teknisk allvarlighetsgrad (CVSSv4), affärspåverkan och tillgänglighet för utnyttjande till ett enda nummer. Det är din åtgärdskö - sortera efter Prioritet för att veta vad som ska hanteras omedelbart. Prioritet 85 betyder “släpp allt och åtgärda detta nu”, medan Prioritet 45 betyder “schemalägg det till nästa sprint.”
Exempel: Fjärrkodexekvering (RCE) i en föråldrad stagingtjänst
En äldre stagingtjänst innehåller en sårbarhet för fjärrkodexekvering. Tjänsten körs tekniskt sett fortfarande men används inte, är inte ansluten till produktion, och är endast tillgänglig från en intern IP-allowlist.
- CVSSv4: 9.8 (kritisk teknisk allvarlighetsgrad)
- Affärspåverkan: 30 (ingen produktionsdata, ingen kundpåverkan, föråldrad tjänst)
- Tillgänglighet för utnyttjande: 35 (kräver intern nätverksåtkomst och tjänstespecifik kunskap)
- Prioritet: 42
Varför titta på Prioritet:
På papper skriker CVSSv4 (9.8) “kritisk”. Om du bara tittade på CVSS, skulle detta utlösa panik och brandövningar.
Prioritet (42) berättar den verkliga historien.
Eftersom tjänsten är föråldrad, isolerad från produktion och inte innehåller känslig data, är den faktiska risken för verksamheten låg. Prioritet nedgraderar korrekt brådskan och säger:
“Åtgärda detta under schemalagd städning eller avveckling, inte som en nödsituation.”
Detta hjälper team att undvika att slösa tid på att dra ingenjörer från kritiskt arbete för att åtgärda en sårbarhet i ett system som redan är på väg ut.
b) Påverkan
Vad det mäter: Affärskonsekvenser
Påverkan (0-100) utvärderar vad som händer om sårbarheten utnyttjas, med hänsyn till din specifika kontext: datasensitivitet, systemkritikalitet, affärsverksamhet och regulatorisk efterlevnad.
Exempel: Hårdkodade molnuppgifter exponerade i ett arkiv
En uppsättning molnåtkomstnycklar har av misstag åtagits till ett Git-arkiv.
- Påverkan 90: Nycklarna tillhör ett produktionsmolnkonto med behörighet att läsa kunddata och skapa infrastruktur. Utnyttjande kan leda till dataintrång, tjänsteavbrott och efterlevnadsbrott.
- Påverkan 25: Nycklarna tillhör ett sandlådekonto utan känsliga data, strikta utgiftsbegränsningar och ingen åtkomst till produktionssystem. Även om de missbrukas är affärspåverkan minimal.
Varför påverkan är viktig:
Sårbarheten är densamma: exponerade uppgifter, men affärskonsekvenserna är radikalt olika. Påverkanspoäng återspeglar vad angriparen faktiskt kan påverka, inte bara vad som gick fel tekniskt.
c) EPSS
Vad det mäter: Sannolikhet för verkliga hot
EPSS är en poäng (0,0-1,0) som förutspår sannolikheten att en specifik CVE kommer att utnyttjas i det vilda inom de närmaste 30 dagarna
Exempel: Två sårbarheter med mycket olika verkliga risker
Sårbarhet A: En kritisk fjärrkodexekveringsbrist från 2014
- CVSS: 9.0 (mycket allvarlig på papper)
- EPSS: 0.02
- Kontekst: Sårbarheten är välkänd, patchar har funnits tillgängliga i flera år, och det finns lite till ingen aktiv exploatering idag.
Sårbarhet B: En nyligen avslöjad autentiseringsförbigång
- CVSS: 6.3 (medel teknisk allvarlighetsgrad)
- EPSS: 0.88
- Kontekst: Proof-of-concept-exploateringar är offentliga, angripare söker aktivt efter dem, och exploatering har redan observerats.
Varför titta på EPSS:
CVSS berättar hur allvarlig en sårbarhet kan vara. EPSS berättar hur sannolikt det är att den attackeras just nu.
Även om Sårbarhet A har en mycket högre CVSS-poäng, visar EPSS att det är osannolikt att den kommer att exploateras inom den närmaste tiden. Sårbarhet B, trots sin lägre CVSS-poäng, representerar ett mer omedelbart hot och bör prioriteras först.
Detta hjälper team att fokusera på verkliga attacker som händer idag, inte bara teoretiska värsta fall.
Du kan kontrollera dessa metoder för prioritering genom att följa dessa steg:
- Se till att ditt arkiv är anslutet och att skanningsprocessen har avslutats.
- Gå sedan till menyn Findings för att hitta de metoder du behöver för prioritering.
Viktiga skillnader
| Metrik | Svar | Omfattning | Intervall |
|---|---|---|---|
| EPSS | “Använder angripare detta?” | Globalt hotlandskap | 0.0-1.0 |
| Prioritet | “Vad ska jag fixa först?” | Kombinerad brådskande poäng | 0-100 |
| Påverkan | “Hur illa för MITT företag?” | Organisationsspecifik | 0-100 |
Steg 3: Åtgärda sårbarheter
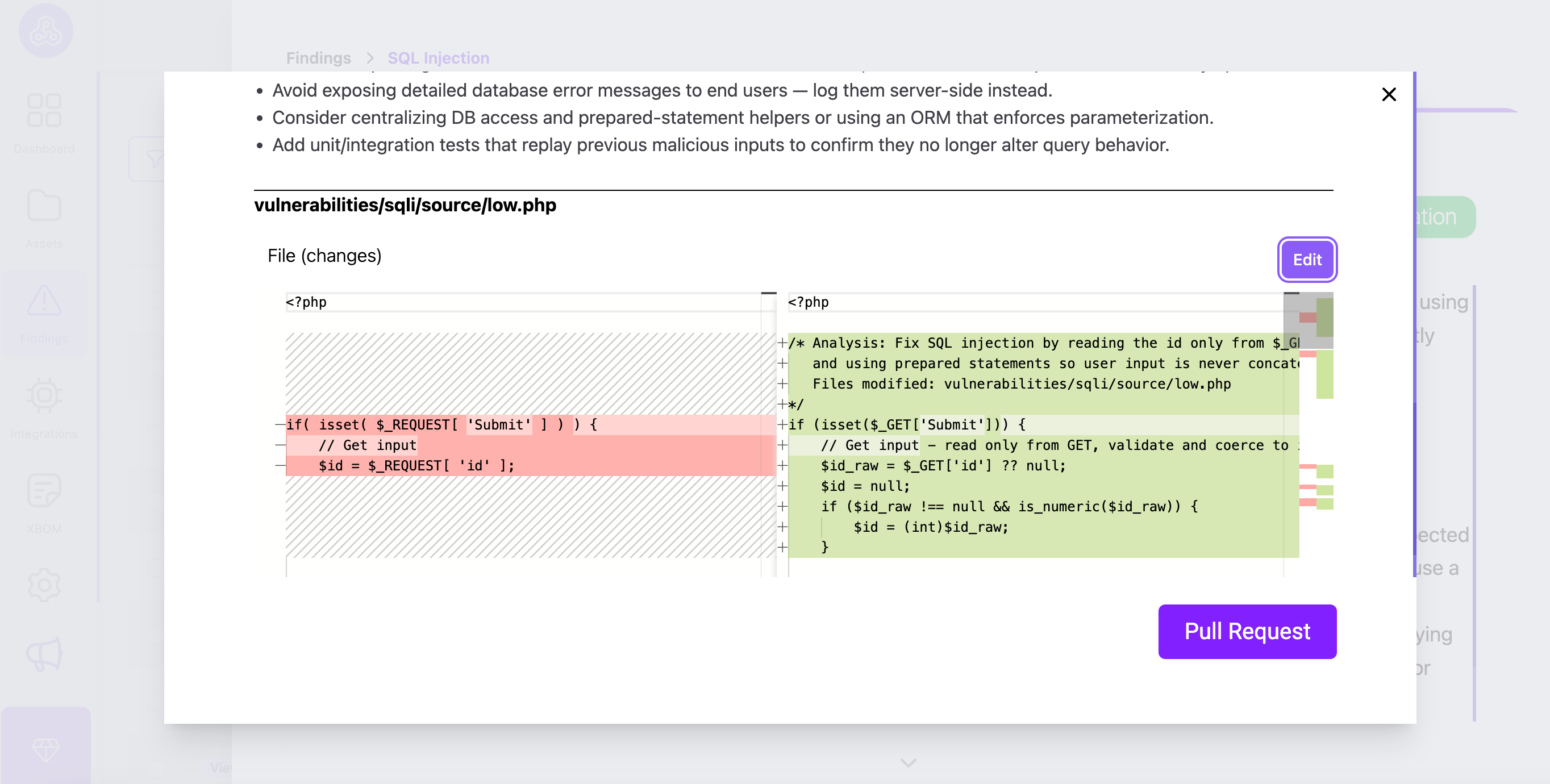
Detta är där de flesta arbetsflöden misslyckas. Att säga till en utvecklare “du har en SQL-injektion” kräver att de forskar om lösningen. Denna friktion leder till ignorerade varningar.
Plexicus åtgärdar sårbarheter automatiskt. Istället för att bara markera ett problem, analyserar plexicus den sårbara kodblocket och föreslår den exakta kodfixen.
Utvecklaren behöver inte gå till Stack Overflow för att hitta en lösning. De granskar helt enkelt den föreslagna patchen och accepterar den. Detta förvandlar en 1-timmes forskningsuppgift till en 1-minuts granskningsuppgift.
Steg 4: PR Dekoration
Att få en utvecklare att öppna ett nytt verktyg för att se fel är en arbetsflödesdödare. Fynd måste visas där utvecklaren redan arbetar.
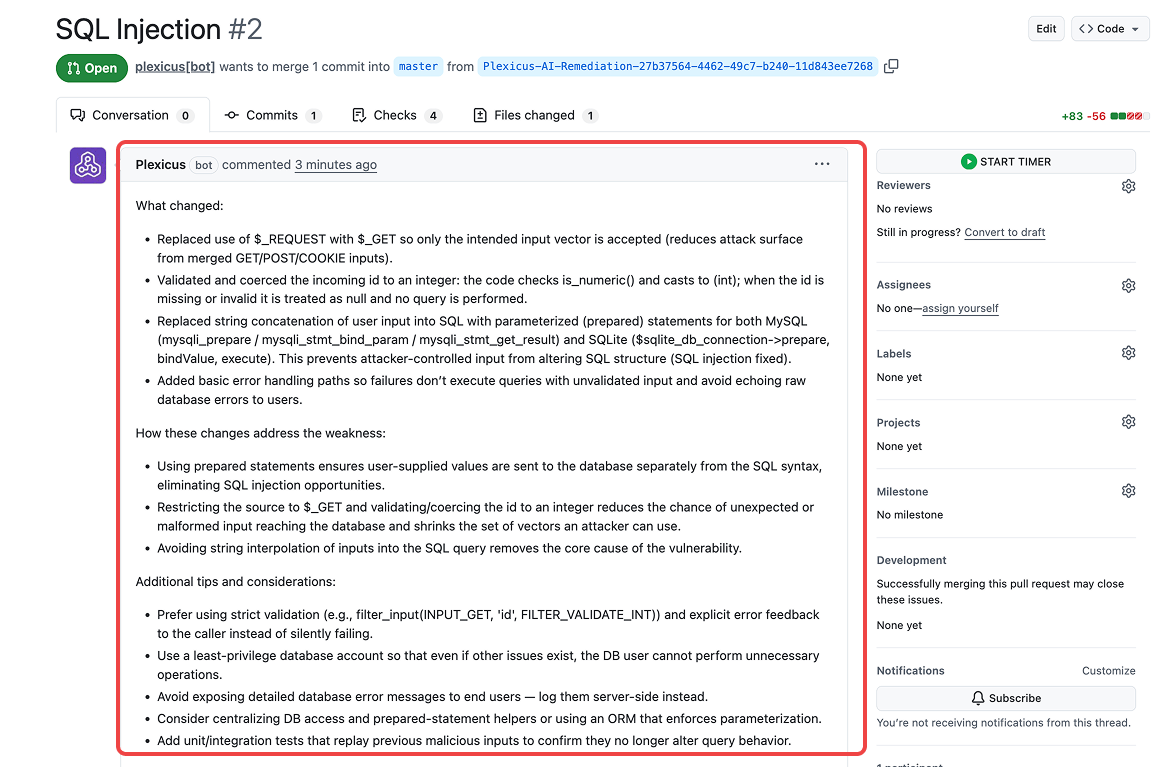
Plexicus använder PR-dekorationer för att posta fynd direkt som kommentarer på de specifika kodrader som ändrats.
- Gammalt sätt: “Bygg misslyckades. Kontrollera felloggar.” (Utvecklaren spenderar 20 minuter på att söka i loggar).
- Nytt sätt: Plexicus kommenterar på Rad 42: “Hög allvarlighet: AWS-nyckel upptäckt här. Vänligen ta bort.”
Steg 4: CI Gating
Till skillnad från traditionella CI-grindar som bara blockerar, genererar Plexicus automatiskt lösningar och skapar pull requests med åtgärdskod. Detta innebär att när en grind blockerar en sammanslagning, får utvecklare färdiga att slå samman fix-PR
, vilket minskar friktionen.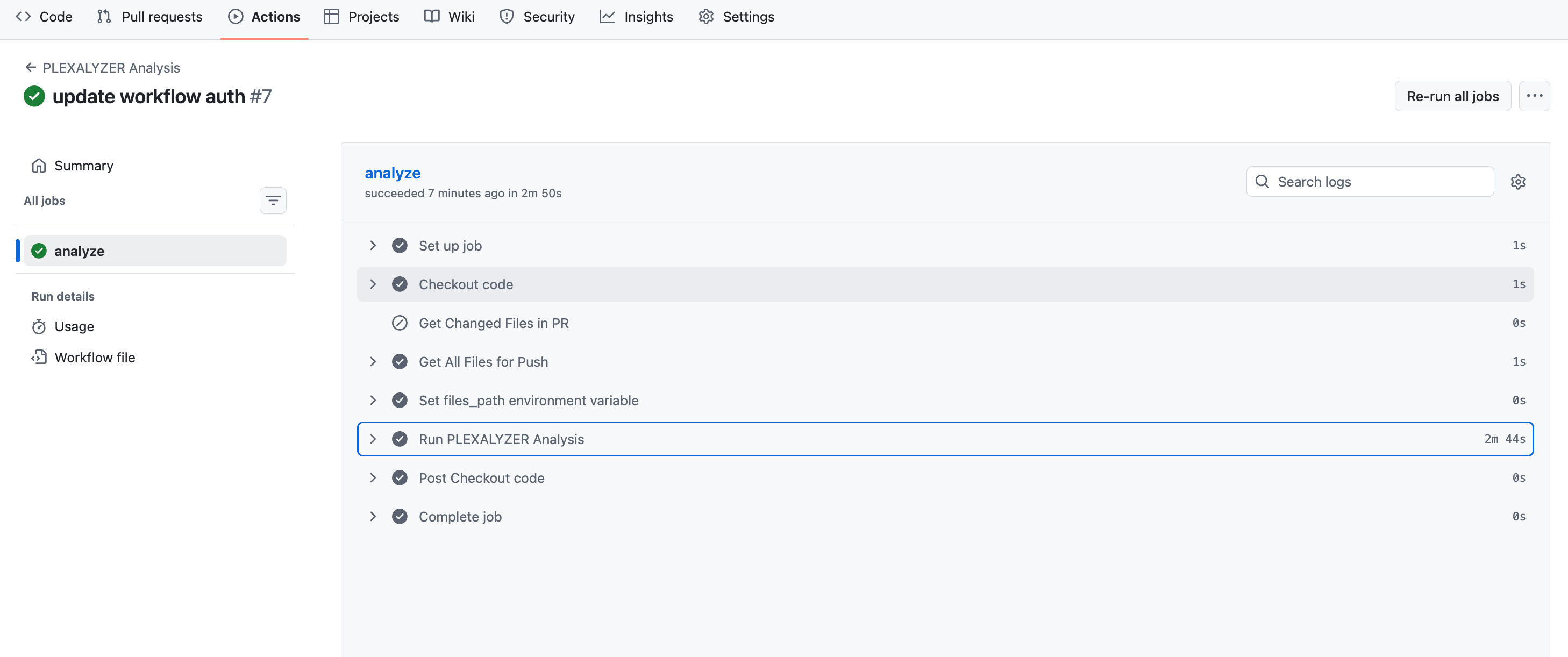
Jämförelse: Legacy-skannrar vs. Plexicus
| Funktion | Legacy-säkerhetsverktyg | Plexicus |
|---|---|---|
| Integrationspunkt | Separat Dashboard / Nattlig skanning | CI/CD Pipeline (Omedelbar) |
| Feedbackloop | PDF-rapporter eller konsolloggar | PR-dekorationer (In-Flow-kommentarer) |
| Åtgärdsbarhet | “Här är ett problem” | “Här är AI-åtgärdsfixen” |
| Tid till fix | Dagar (Kräver kontextbyte) | Minuter (Under kodgranskning) |
Viktigt att ta med sig
Utvecklare ignorerar inte säkerhetsfynd för att de är lata. De ignorerar dem för att verktygen är ineffektiva och störande.
Genom att flytta säkerheten in i CI/CD-pipelinen ändrar du dynamiken. Du ber inte utvecklare att “sluta arbeta och göra säkerhet”; du gör säkerhet till en del av kodgranskningen de redan gör.
När du använder verktyg som Plexicus, stänger du loopen helt. Du upptäcker problemet i pipelinen, lyfter fram det i PR
och tillämpar Plexicus AI-åtgärdsfixen.Redo att städa upp din pipeline?
Börja med att skanna din nästa Pull Request efter hemligheter, och låt Plexicus hantera åtgärdandet. Plexicus integreras sömlöst med populära CI/CD-plattformar som Jenkins eller GitHub Actions, samt versionskontrollsystem som GitHub, GitLab och Bitbucket. Denna kompatibilitet säkerställer att det passar smidigt in i din befintliga verktygskedja, vilket gör säkerhetsförbättring till en enkel del av ditt utvecklingsflöde.
Plexicus erbjuder också en gratis Community Tier för att hjälpa dig säkra din kod omedelbart. För mer information, kolla in prissidan. Kom igång idag, utan kostnad, utan hinder.
Vanliga Frågor (FAQ)
1. Vad är Plexicus?
Plexicus är en CNAPP- och ASPM-plattform som integreras direkt i din CI/CD-pipeline, vilket hjälper dig att upptäcka och åtgärda sårbarheter, hemligheter och kodproblem så snart koden trycks.
2. Hur hjälper Plexicus utvecklare att åtgärda sårbarheter snabbare?
Plexicus flyttar säkerhetsskanning till Pull Request (PR)-stadiet, flaggar omedelbart problem och ger föreslagna kodfixar. Detta minskar tiden och ansträngningen som krävs för åtgärdande och hjälper till att förhindra varningströtthet.
3. Vilka typer av problem upptäcker Plexicus?
Plexicus upptäcker flera typer av säkerhetsproblem över hela SDLC, inklusive: hemligheter i kod (exponerade referenser, API-nycklar), statisk kodsårbarhet (SAST), beroendesårbarheter (SCA), infrastruktur som kodfelkonfigurationer, containersäkerhetsproblem, molnsäkerhetsställning, CI/CD-pipeline säkerhet, licensöverensstämmelse och dynamiska applikationssårbarheter (DAST). Plattformen integrerar 20+ säkerhetsverktyg för att ge omfattande täckning av applikationssäkerhet.
4. Hur prioriterar Plexicus sårbarheter?
Plexicus använder tre nyckelmetrik: Prioritet (kombinerar allvarlighetsgrad, affärspåverkan och exploaterbarhet), Påverkan (affärskonsekvenser) och EPSS (sannolikhet för verklig exploatering). Dessa hjälper team att fokusera på de mest akuta och påverkningsfulla problemen.
5. Fixar Plexicus automatiskt sårbarheter?
Ja, Plexicus analyserar sårbar kod och föreslår patchar som utvecklare kan granska och acceptera direkt inom PR, vilket minimerar manuellt forskningsarbete.
6. Hur kommuniceras fynd till utvecklare?
Fynd publiceras som PR-dekorationer, kommentarer på specifika kodrader inom PR, så att utvecklare ser dem där de redan arbetar.
7. Vilka CI/CD-plattformar och versionskontrollsystem stöder Plexicus?
Plexicus integreras med populära CI/CD-plattformar som Jenkins och GitHub Actions, och fungerar med versionskontrollsystem inklusive GitHub, GitLab och Bitbucket.
8. Finns det en gratisversion av Plexicus?
Ja, Plexicus erbjuder en gratis Community Tier. Du kan börja utan kostnad. Kolla in prissidan för detaljer.
9. Varför ignorerar utvecklare ofta säkerhetsfynd?
Utvecklare ignorerar ofta fynd eftersom säkerhetsverktyg kan vara störande, bullriga och tidskrävande. Plexicus adresserar detta genom att göra säkerhet till en del av det befintliga arbetsflödet och tillhandahålla handlingsbara lösningar.



