Tiempo Medio de Remediación (MTTR)
En Resumen
- MTTR representa el tiempo promedio requerido para resolver una vulnerabilidad de seguridad después de su identificación, proporcionando una medida directa de la eficiencia operativa.
- Para calcular el MTTR, divide el tiempo total dedicado a solucionar problemas por el número de incidentes.
- El objetivo es minimizar el tiempo de exposición para que los atacantes tengan menos probabilidades de explotar brechas conocidas.
- La solución es acelerar el proceso automatizando todo, desde la detección de vulnerabilidades hasta la generación de correcciones de código, eliminando retrasos en las colas de tickets manuales y asegurando una remediación más rápida.
Qué es el MTTR?
El Tiempo Medio de Remediación (MTTR) es una métrica clave de ciberseguridad que muestra qué tan rápido respondes a una amenaza conocida. Mide el tiempo desde que se encuentra una vulnerabilidad hasta que se implementa una solución.
Mientras que métricas como el MTTD reflejan la velocidad de detección, el MTTR revela la verdadera eficiencia de remediación de tu organización. La detección rápida debe ir acompañada de una resolución pronta para contener la exposición al riesgo y apoyar la continuidad del negocio.
Por Qué Importa el MTTR
Los ciberdelincuentes operan más rápido que los cronogramas de desarrollo tradicionales, acelerando la demanda de operaciones de seguridad receptivas. Las tendencias de la industria indican que las ventanas de defensa se están reduciendo.
- La ventana de explotación de 5 días: En 2025, el promedio de Tiempo para Explotar (TTE), el intervalo entre cuando una vulnerabilidad se hace pública y cuando es explotada activamente, cayó de 32 días a solo 5 días (CyberMindr, 2025).
- Aumento de la explotación: El uso de vulnerabilidades como una vía de entrada ha aumentado un 34% este año y ahora causa el 20% de todas las brechas confirmadas.
- El retraso en la remediación: Los atacantes actúan en días, pero las organizaciones a menudo tardan semanas. El tiempo medio para corregir vulnerabilidades críticas en dispositivos de borde y VPN sigue siendo de 32 días, dejando una ventana de riesgo significativa. Solo el 54% de los fallos se parchean completamente (Verizon DBIR, 2025). Aceleración del día: El descubrimiento de vulnerabilidades de día cero explotadas aumentó un 46% en comparación con el año pasado. Los atacantes ahora convierten estas fallas en armas dentro de horas de su identificación (WithSecure Labs, 2025).
- Alto MTTR incrementa los costos empresariales mucho más allá de la deuda técnica. En 2025, el costo promedio de una brecha de datos en EE.UU. es de $4.4 millones, principalmente debido a la respuesta tardía y las sanciones regulatorias (IBM, 2025).
- Sanciones por incumplimiento: Bajo reglas como DORA, los largos tiempos de exposición cuentan como fallas bajo la resiliencia operativa. Las organizaciones con alto MTTR ahora enfrentan informes obligatorios y grandes multas por incumplimiento. No puedes moverte más rápido que los scripts de explotación; tu defensa es puramente teórica.
Cómo Calcular MTTR
MTTR se calcula dividiendo el tiempo total dedicado a reparar un sistema por el número de reparaciones realizadas durante un período específico.
La Fórmula
{kind=link}
Ejemplo de Cálculo
Imagina que tu equipo de ingeniería manejó 4 incidentes el mes pasado:
- Incidente A: Caída de la base de datos (Reparado en 30 minutos)
- Incidente B: Fallo del API (Reparado en 2 horas / 120 minutos)
- Incidente C: Error de caché (Reparado en 15 minutos)
- Incidente D: Parche de seguridad (Reparado en 45 minutos)
- Tiempo Total de Reparación: 30 + 120 + 15 + 45 = 210 minutos
- Número de Reparaciones: 4
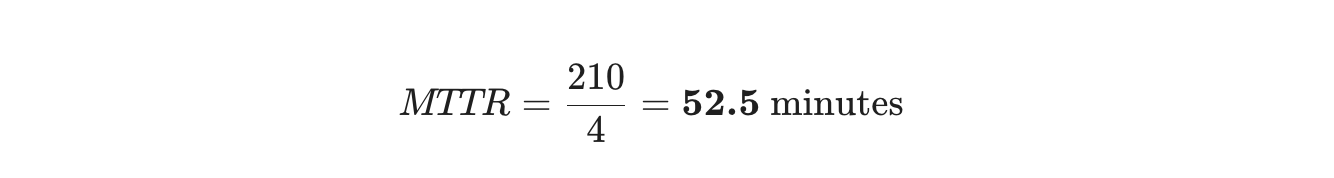{kind=link}
Esto significa que, en promedio, tu equipo tarda aproximadamente 52 minutos en solucionar un problema una vez que comienzan a trabajar en él.
Ejemplo en la Práctica
Considera dos empresas enfrentando una vulnerabilidad crítica de seguridad (por ejemplo, Log4Shell).
Empresa A (Alto MTTR):
- Proceso: Manual. Las alertas van al correo electrónico. Un ingeniero tiene que acceder manualmente a los servidores mediante SSH para encontrar los archivos jar vulnerables y parchearlos uno por uno.
- MTTR: 48 Horas.
- Resultado: Los atacantes tienen dos días completos para explotar la vulnerabilidad. Es probable que los datos estén comprometidos.
Empresa B (Bajo MTTR - usando Plexicus para automatizar la remediación):
- Proceso: Automatizado. La vulnerabilidad se detecta inmediatamente. Un libro de jugadas automatizado se activa para aislar los contenedores afectados y aplicar un parche o una regla de firewall virtual.
- MTTR: 15 Minutos.
- Resultado: La vulnerabilidad se cierra antes de que los atacantes puedan lanzar un exploit exitoso.
Quién Usa MTTR
- Ingenieros DevOps - Para rastrear la eficiencia de sus pipelines de despliegue y retroceso.
- SREs (Ingenieros de Confiabilidad del Sitio) - Aseguran que cumplen con los SLA (Acuerdos de Nivel de Servicio) para el tiempo de actividad.
- Analistas SOC - Para medir qué tan rápido pueden neutralizar amenazas de seguridad activas.
- CTOs y CISOs - Para justificar inversiones en herramientas de automatización mostrando una reducción en el tiempo de recuperación.
Cuándo Aplicar MTTR
El MTTR debe ser monitoreado continuamente, pero es más crítico durante la fase de Respuesta a Incidentes del SDLC (Ciclo de Vida de Desarrollo de Software)
- Durante Incidentes: Actúa como un chequeo de pulso en vivo. “¿Estamos solucionando esto lo suficientemente rápido?”
- Post-Mortem: Después de un incidente, revisar el MTTR ayuda a identificar si la demora fue causada por detectar el problema (MTTD) o solucionarlo (MTTR).
- Negociación de SLA: No se puede prometer a un cliente “99.99% de tiempo de actividad” si su MTTR promedio es de 4 horas.
Mejores Prácticas para Reducir MTTR
- Automatizar todo: Las correcciones manuales son lentas y propensas a errores. Utiliza Infraestructura como Código (IaC) para reimplementar la infraestructura rota en lugar de arreglarla manualmente.
- Mejor monitoreo: No puedes arreglar lo que no puedes ver. Las herramientas de observabilidad granular ayudan a identificar la causa raíz más rápido, reduciendo la parte de “diagnóstico” del tiempo de reparación.
- Runbooks y Playbooks: Ten guías preescritas para fallos comunes. Si una base de datos se bloquea, el ingeniero no debería tener que buscar en Google “cómo desbloquear una base de datos”.
- Post-mortems sin culpabilidad: Enfócate en la mejora del proceso, no en las personas. Si los ingenieros temen el castigo, podrían ocultar fallos, haciendo que las métricas de MTTR sean inexactas.
Términos relacionados
- MTTD (Tiempo Medio para Detectar)
- MTBF (Tiempo Medio Entre Fallos)
- SLA (Acuerdo de Nivel de Servicio)
- Gestión de Incidentes
Mitos comunes
-
Mito: Puedes alcanzar “cero vulnerabilidades.”
Realidad: El objetivo es solucionar problemas críticos lo suficientemente rápido como para evitar la explotación.
-
Mito: Más escáneres equivalen a mejor seguridad.
En realidad, agregar herramientas solo crea más ruido y trabajo manual si no están integradas.
-
Mito: Las herramientas de seguridad ralentizan a los desarrolladores.
Realidad: La seguridad solo ralentiza a los desarrolladores cuando genera alertas “rotas”. Cuando proporcionas una solicitud de extracción preescrita, les ahorras horas de investigación.
FAQ
¿Qué es un “buen” MTTR?
Los mejores equipos de DevOps apuntan a un MTTR de menos de 24 horas para vulnerabilidades críticas.
¿Cómo difiere el MTTR del MTTD?
MTTD (Tiempo Medio para Detectar) muestra cuánto tiempo está presente una amenaza antes de que la notes. MTTR muestra cuánto tiempo permanece después de que la has encontrado.
¿Puede la IA realmente ayudar con el MTTR?
Sí. Herramientas de IA como Plexicus manejan el triaje y sugieren soluciones, lo que típicamente representa el 80% del proceso de remediación.
Pensamiento Final
El MTTR es el latido de tu programa de seguridad. Si es alto, tu riesgo es alto. Al automatizar la transición de encontrar problemas a crear solicitudes de extracción, dejas de tratar la seguridad como un cuello de botella y comienzas a tratarla como una parte normal de tu pipeline CI/CD.